La roue cryptographique
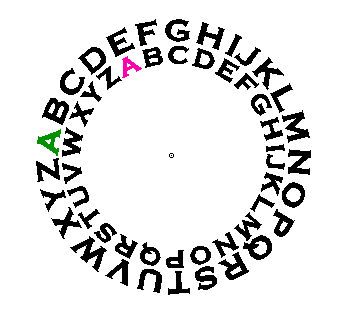
L'étude des codes secrets est un passe-temps enfantin : on fait circuler ouvertement un message qui ne peut être lu que si on possède aussi la clef de son code. Le jeu consiste à exercer un pouvoir imaginaire sur les êtres qui ignorent la clef. C'est un jeu parce qu'on n'a véritablement rien à cacher. Pour peu qu'on garde un peu de son innocence par la suite, le plaisir de composer ou de casser un code secret demeure. C'est la cryptographie "douce".
La cryptographie dite "dure" se distingue de la première sorte par l'usage qu'on en a : on a réellement quelque chose à cacher et on transmet les messages sous une forme réellement indéchiffrable. Nous ignorons bien des choses sans nous en plaindre et c'est pourquoi je ne m'attarderai pas longtemps ici sur le thème de la cryptographie dure. Elle est certes plus complexe mais elle n'est pas distincte techniquement de la première.
La cryptographie apparaît enfin au quotidien dans l'outil informatique comme un moyen efficace d'assurer la non-compatibilité des machines, des systèmes ou des logiciels différents. C'est la troisième sorte, que j'appelle la cryptographie "molle". Voilà une chose parfaitement inutile que je choisis de combattre.
L'objet classique est composé de deux disques concentriques glissant l'un sur l'autre. La lettre à encoder se lit par exemple sur le disque extérieur et son code est juxtaposé sur le disque intérieur. On peut naturellement formuler l'alphabet dans le désordre. Pour décoder le message, il suffit d'avoir une roue de formulation identique dont les disques sont positionnés de la même façon. Ces deux critères, la formule et la position ou clef, représentent la solution du code.
Ce genre de jouet attire l'informaticien comme l'aimant attire la limaille de fer. En utilisant un programme d'ordinateur à la place du disque physique, on peut optimiser la roue dont l'application devient instantanée. Le "problème du code secret" est d'ailleurs archi-classique pour les programmeurs.
On n'a pas besoin de la science des fusées pour comprendre comment, en généralisant le principe de la roue cryptographique, on peut créer un code incassable. Il suffit de la tourner un très grand nombre de fois. Le temps nécessaire pour casser le code devient vite un paramètre assez banal et qu'on contrôle assez librement. On doit considérer aujourd'hui la fabrication d'un code secret incassable comme un exercice de style, rien de plus. Cet exercice débouche sur des ramifications fascinantes mais, pour ce qui est de la conception du codage, c'est relativement trivial. Les ramifications techniques ne sont d'ailleurs pas nouvelles :
Un cas trivial illustre très bien l'essence du code incassable : Disons que j'envoie le message "X" (un seul caractère) et que vous l'interceptez. Vous pouvez toujours tâtonner ! Le code "X" peut signifier "allons au cinéma ce soir" ou "prends une pizza en rentrant" ou même "X". Vous êtes bien avancé. Le seul moyen connu aujourd'hui pour casser un code "dur" est "l'ingénieurie sociale". On ne cherche pas à casser le code par un moyen mécanique ou technique. On s'arrange plutôt pour rencontrer quelqu'un qui connaît la formule et la clef (ou le message lui-même) et on lui demande de les dévoiler. C'est aussi simple que ça.
Pour comprendre l'encodage des caractères, les difficultés techniques sont vite cernées : il suffit d'une roue cryptographique. Heureusement, nous en avons une, normalisée pour toutes les machines et tous les systèmes : le format ASCII. Malheureusement, cette roue normalisée n'inclut pas tous les caractères français.
| ASCII |
|---|
 |
Le texte est représenté dans les fichiers de l'ordinateur par des codes ASCII numériques. L'ordinateur utilise la roue cryptographique pour convertir chaque code en un caractère lisible avant d'afficher le texte. Exemple : le message codé "87 69 66" signifie "WEB".
L'incompatibilité des fichiers issus de machines différentes vient de ce que la roue a ensuite été aggrandie pour inclure les caractères accentués par exemple sans qu'aucune nouvelle norme ne soit adoptée. Chaque machine adopte donc une formule différente. Le problème est facile à mettre en évidence.
| Prenons un exemple au hasard : |  |
| Disons maintenant que ce texte est saisi sur un Mac et lu sur une machine Windows. On obtient comme par magie et sans effort : |  |
| Inversement, si on saisit le même texte sur une machine Windows et qu'on le lit sur un Mac, on est immédiatement gratifié par : |  |
Les roues ne sont pas les mêmes. Ce cryptage mou "réussit" uniquement par l'agacement qu'il procure. Le terme "ascii étendu" pour cette nouvelle famille de roues est incorrect. L'ASCII (American Standard Code for Information Interchange) est une norme et l'ascii étendu ne l'est pas ! On pourrait demander pourquoi cette situation perdure (au moins jusqu'en 1998 quand j'écris ceci) ! Microsoft répond que c'est seulement le problème des gens qui n'ont pas eu la sagesse de choisir le système windows et qu'ils n'ont qu'à le résoudre eux-mêmes.
Pour le web, il faut normaliser. Le premier codage normalisé pour le web se nomme "Latin-1" ou "ISO-8859-1". ISO Latin I ajoute aux codes ASCII, de 32 à 127, des nouveaux caractères se codant entre 160 et 255. La spécification du langage html impose au logiciel butineur d'insérer une nouvelle roue cryptographique dans le codage pour ces caractères (en plus de la roue propre à la machine). On pourrait penser que le problème est résolu. Ce n'est pas le cas.
| "ascii étendu" pseudo-latin mswindows 98 |
|---|
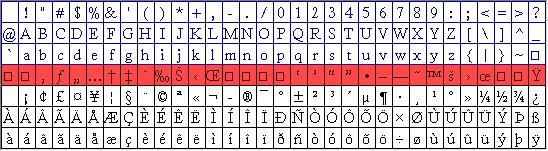 |
| Nouveau en 2002 : les choses s'arrangent. En effet, windows me a fini par apprendre à afficher tous les caractères français présents dans le web. Il n'a pas pour autant appris à les taper au clavier et msword2000 n'est toujours pas conforme à la norme HTML - pourtant en vigueur depuis 1998 ! |
Il existe une norme plus intéressante, ISO 10646, qui définit une liste comprenant des milliers de caractères. La nouvelle norme inclut et dépasse le Latin I. Les éléments les plus courants de cette liste dans l'usage européen sont énumérés plus loin. Cette norme figure dans HTML 4.0 en avril 1998. C'est, en théorie, l'ultime outil d'écriture pour le web.
Le codage supplémentaire réclamé par le html est le suivant :
| Exemple : la lettre accentuée "é" peut se représenter par "é" ou "é". Le codage "233" (ascii étendu) utilisé par msword2000 est incorrect puisqu'il est ambigu. La recommandation html 4.0 préconise l'utilisation du nom plutôt que le code numérique. |
| Quand un logiciel ne connaît pas le code, le descripteur est laissé tel quel, ce qui assure toujours un minimum d'intelligibilité : |  |
Les constructeurs de machines et de logiciels peuvent désormais utiliser les roues internes qu'ils veulent, il leur suffit de savoir décoder les entités ISO. En utilisant les entités, nous autres constructeurs de pages web sommes sûrs de respecter toujours le format ASCII (96 caractères), la seule norme en vigueur aujourd'hui encore pour les fichiers texte.
Dans les tableaux qui vont suivre, les codes numériques sont donnés en base hexadécimale. Si vous voulez écrire ces codes numériques (déconseillés) ouvrez ce document avec un éditeur de pages en mode "source" où vous pourrez lire les codes décimaux. Les codes décimaux et les entités sont interprétés par le butineur. Si vous voyez un carré blanc à la place du symbole voulu, c'est que votre ordinateur n'affiche pas le caractère en question - mais vous pouvez en principe vous en servir puisque le caractère est conforme au html en vertu de sa seule présence dans ces listes.
[ Extrait de la section 5 "Document Representation" de "HTML 4.0 Specification, W3C Recommendation, revised on 24-Apr-1998 ]
Source : http://www.w3.org/TR/1998/REC-html40-19980424
The ASCII character set is not sufficient for a global information system such as the Web, so HTML uses the much more complete character set called the Universal Character Set (UCS), defined in [ISO10646]. This standard defines a repertoire of thousands of characters used by communities all over the world. The character set defined in [ISO10646] is character-by-character equivalent to Unicode 2.0 ([UNICODE]). Both of these standards are updated from time to time with new characters, and the amendments should be consulted at the respective Web sites. In the current specification, references to ISO/IEC-10646 or Unicode imply the same document character set. However, the HTML specification also refers to the Unicode specification for other issues such as the bidirectional text algorithm.
[ Section 24 de "HTML 4.0 Specification, W3C Recommendation, revised on 24-Apr-1998 ]
Source : http://www.w3.org/TR/1998/REC-html40-19980424
24 Character entity references in HTML 4.0
Contents
1. Introduction to character entity references
2. Character entity references for ISO 8859-1 characters
1. The list of characters
3. Character entity references for symbols, mathematical symbols, and
Greek letters
1. The list of characters
4. Character entity references for markup-significant and
internationalization characters
1. The list of characters
24.1 Introduction to character entity references
A character entity reference is an SGML construct that references a
character of the document character set.
This version of HTML supports several sets of character entity references:
* ISO 8859-1 (Latin-1) characters In accordance with section 14 of
[RFC1866], the set of Latin-1 entities has been extended by this
specification to cover the whole right part of ISO-8859-1 (all code
positions with the high-order bit set), including the already commonly
used , © and ®. The names of the entities are taken from
the appendices of SGML (defined in [ISO8879]).
* symbols, mathematical symbols, and Greek letters. These characters may
be represented by glyphs in the Adobe font "Symbol".
* markup-significant and internationalization characters (e.g., for
bidirectional text).
The following sections present the complete lists of character entity
references. Although, by convention, [ISO10646] the comments following each
entry are usually written with uppercase letters, we have converted them to
lowercase in this specification for reasons of readability.
24.2 Character entity references for ISO 8859-1 characters
The character entity references in this section produce characters whose
numeric equivalents should already be supported by conforming HTML 2.0 user
agents. Thus, the character entity reference ÷ is a more convenient
form than ÷ for obtaining the division sign (�).
To support these named entities, user agents need only recognize the entity
names and convert them to characters that lie within the repertoire of
[ISO88591].
Character 65533 (FFFD hexadecimal) is the last valid character in UCS-2.
65534 (FFFE hexadecimal) is unassigned and reserved as the byte-swapped
version of ZERO WIDTH NON-BREAKING SPACE for byte-order detection purposes.
65535 (FFFF hexadecimal) is unassigned.
24.2.1 The list of characters
<!-- Portions © International Organization for Standardization 1986
Permission to copy in any form is granted for use with
conforming SGML systems and applications as defined in
ISO 8879, provided this notice is included in all copies.
-->
<!-- Character entity set. Typical invocation:
<!ENTITY % HTMLlat1 PUBLIC
"-//W3C//ENTITIES Latin 1//EN//HTML">
%HTMLlat1;
-->
<!ENTITY nbsp CDATA " " -- no-break space = non-breaking space,
U+00A0 ISOnum -->
<!ENTITY iexcl CDATA "¡" -- inverted exclamation mark, U+00A1 ISOnum -->
<!ENTITY cent CDATA "¢" -- cent sign, U+00A2 ISOnum -->
<!ENTITY pound CDATA "£" -- pound sign, U+00A3 ISOnum -->
<!ENTITY curren CDATA "¤" -- currency sign, U+00A4 ISOnum -->
<!ENTITY yen CDATA "¥" -- yen sign = yuan sign, U+00A5 ISOnum -->
<!ENTITY brvbar CDATA "¦" -- broken bar = broken vertical bar,
U+00A6 ISOnum -->
<!ENTITY sect CDATA "§" -- section sign, U+00A7 ISOnum -->
<!ENTITY uml CDATA "¨" -- diaeresis = spacing diaeresis,
U+00A8 ISOdia -->
<!ENTITY copy CDATA "©" -- copyright sign, U+00A9 ISOnum -->
<!ENTITY ordf CDATA "ª" -- feminine ordinal indicator, U+00AA ISOnum -->
<!ENTITY laquo CDATA "«" -- left-pointing double angle quotation mark
= left pointing guillemet, U+00AB ISOnum -->
<!ENTITY not CDATA "¬" -- not sign, U+00AC ISOnum -->
<!ENTITY shy CDATA "" -- soft hyphen = discretionary hyphen,
U+00AD ISOnum -->
<!ENTITY reg CDATA "®" -- registered sign = registered trade mark sign,
U+00AE ISOnum -->
<!ENTITY macr CDATA "¯" -- macron = spacing macron = overline
= APL overbar, U+00AF ISOdia -->
<!ENTITY deg CDATA "°" -- degree sign, U+00B0 ISOnum -->
<!ENTITY plusmn CDATA "±" -- plus-minus sign = plus-or-minus sign,
U+00B1 ISOnum -->
<!ENTITY sup2 CDATA "²" -- superscript two = superscript digit two
= squared, U+00B2 ISOnum -->
<!ENTITY sup3 CDATA "³" -- superscript three = superscript digit three
= cubed, U+00B3 ISOnum -->
<!ENTITY acute CDATA "´" -- acute accent = spacing acute,
U+00B4 ISOdia -->
<!ENTITY micro CDATA "µ" -- micro sign, U+00B5 ISOnum -->
<!ENTITY para CDATA "¶" -- pilcrow sign = paragraph sign,
U+00B6 ISOnum -->
<!ENTITY middot CDATA "·" -- middle dot = Georgian comma
= Greek middle dot, U+00B7 ISOnum -->
<!ENTITY cedil CDATA "¸" -- cedilla = spacing cedilla, U+00B8 ISOdia -->
<!ENTITY sup1 CDATA "¹" -- superscript one = superscript digit one,
U+00B9 ISOnum -->
<!ENTITY ordm CDATA "º" -- masculine ordinal indicator,
U+00BA ISOnum -->
<!ENTITY raquo CDATA "»" -- right-pointing double angle quotation mark
= right pointing guillemet, U+00BB ISOnum -->
<!ENTITY frac14 CDATA "¼" -- vulgar fraction one quarter
= fraction one quarter, U+00BC ISOnum -->
<!ENTITY frac12 CDATA "½" -- vulgar fraction one half
= fraction one half, U+00BD ISOnum -->
<!ENTITY frac34 CDATA "¾" -- vulgar fraction three quarters
= fraction three quarters, U+00BE ISOnum -->
<!ENTITY iquest CDATA "¿" -- inverted question mark
= turned question mark, U+00BF ISOnum -->
<!ENTITY Agrave CDATA "À" -- latin capital letter A with grave
= latin capital letter A grave,
U+00C0 ISOlat1 -->
<!ENTITY Aacute CDATA "Á" -- latin capital letter A with acute,
U+00C1 ISOlat1 -->
<!ENTITY Acirc CDATA "Â" -- latin capital letter A with circumflex,
U+00C2 ISOlat1 -->
<!ENTITY Atilde CDATA "Ã" -- latin capital letter A with tilde,
U+00C3 ISOlat1 -->
<!ENTITY Auml CDATA "Ä" -- latin capital letter A with diaeresis,
U+00C4 ISOlat1 -->
<!ENTITY Aring CDATA "Å" -- latin capital letter A with ring above
= latin capital letter A ring,
U+00C5 ISOlat1 -->
<!ENTITY AElig CDATA "Æ" -- latin capital letter AE
= latin capital ligature AE,
U+00C6 ISOlat1 -->
<!ENTITY Ccedil CDATA "Ç" -- latin capital letter C with cedilla,
U+00C7 ISOlat1 -->
<!ENTITY Egrave CDATA "È" -- latin capital letter E with grave,
U+00C8 ISOlat1 -->
<!ENTITY Eacute CDATA "É" -- latin capital letter E with acute,
U+00C9 ISOlat1 -->
<!ENTITY Ecirc CDATA "Ê" -- latin capital letter E with circumflex,
U+00CA ISOlat1 -->
<!ENTITY Euml CDATA "Ë" -- latin capital letter E with diaeresis,
U+00CB ISOlat1 -->
<!ENTITY Igrave CDATA "Ì" -- latin capital letter I with grave,
U+00CC ISOlat1 -->
<!ENTITY Iacute CDATA "Í" -- latin capital letter I with acute,
U+00CD ISOlat1 -->
<!ENTITY Icirc CDATA "Î" -- latin capital letter I with circumflex,
U+00CE ISOlat1 -->
<!ENTITY Iuml CDATA "Ï" -- latin capital letter I with diaeresis,
U+00CF ISOlat1 -->
<!ENTITY ETH CDATA "Ð" -- latin capital letter ETH, U+00D0 ISOlat1 -->
<!ENTITY Ntilde CDATA "Ñ" -- latin capital letter N with tilde,
U+00D1 ISOlat1 -->
<!ENTITY Ograve CDATA "Ò" -- latin capital letter O with grave,
U+00D2 ISOlat1 -->
<!ENTITY Oacute CDATA "Ó" -- latin capital letter O with acute,
U+00D3 ISOlat1 -->
<!ENTITY Ocirc CDATA "Ô" -- latin capital letter O with circumflex,
U+00D4 ISOlat1 -->
<!ENTITY Otilde CDATA "Õ" -- latin capital letter O with tilde,
U+00D5 ISOlat1 -->
<!ENTITY Ouml CDATA "Ö" -- latin capital letter O with diaeresis,
U+00D6 ISOlat1 -->
<!ENTITY times CDATA "×" -- multiplication sign, U+00D7 ISOnum -->
<!ENTITY Oslash CDATA "Ø" -- latin capital letter O with stroke
= latin capital letter O slash,
U+00D8 ISOlat1 -->
<!ENTITY Ugrave CDATA "Ù" -- latin capital letter U with grave,
U+00D9 ISOlat1 -->
<!ENTITY Uacute CDATA "Ú" -- latin capital letter U with acute,
U+00DA ISOlat1 -->
<!ENTITY Ucirc CDATA "Û" -- latin capital letter U with circumflex,
U+00DB ISOlat1 -->
<!ENTITY Uuml CDATA "Ü" -- latin capital letter U with diaeresis,
U+00DC ISOlat1 -->
<!ENTITY Yacute CDATA "Ý" -- latin capital letter Y with acute,
U+00DD ISOlat1 -->
<!ENTITY THORN CDATA "Þ" -- latin capital letter THORN,
U+00DE ISOlat1 -->
<!ENTITY szlig CDATA "ß" -- latin small letter sharp s = ess-zed,
U+00DF ISOlat1 -->
<!ENTITY agrave CDATA "à" -- latin small letter a with grave
= latin small letter a grave,
U+00E0 ISOlat1 -->
<!ENTITY aacute CDATA "á" -- latin small letter a with acute,
U+00E1 ISOlat1 -->
<!ENTITY acirc CDATA "â" -- latin small letter a with circumflex,
U+00E2 ISOlat1 -->
<!ENTITY atilde CDATA "ã" -- latin small letter a with tilde,
U+00E3 ISOlat1 -->
<!ENTITY auml CDATA "ä" -- latin small letter a with diaeresis,
U+00E4 ISOlat1 -->
<!ENTITY aring CDATA "å" -- latin small letter a with ring above
= latin small letter a ring,
U+00E5 ISOlat1 -->
<!ENTITY aelig CDATA "æ" -- latin small letter ae
= latin small ligature ae, U+00E6 ISOlat1 -->
<!ENTITY ccedil CDATA "ç" -- latin small letter c with cedilla,
U+00E7 ISOlat1 -->
<!ENTITY egrave CDATA "è" -- latin small letter e with grave,
U+00E8 ISOlat1 -->
<!ENTITY eacute CDATA "é" -- latin small letter e with acute,
U+00E9 ISOlat1 -->
<!ENTITY ecirc CDATA "ê" -- latin small letter e with circumflex,
U+00EA ISOlat1 -->
<!ENTITY euml CDATA "ë" -- latin small letter e with diaeresis,
U+00EB ISOlat1 -->
<!ENTITY igrave CDATA "ì" -- latin small letter i with grave,
U+00EC ISOlat1 -->
<!ENTITY iacute CDATA "í" -- latin small letter i with acute,
U+00ED ISOlat1 -->
<!ENTITY icirc CDATA "î" -- latin small letter i with circumflex,
U+00EE ISOlat1 -->
<!ENTITY iuml CDATA "ï" -- latin small letter i with diaeresis,
U+00EF ISOlat1 -->
<!ENTITY eth CDATA "ð" -- latin small letter eth, U+00F0 ISOlat1 -->
<!ENTITY ntilde CDATA "ñ" -- latin small letter n with tilde,
U+00F1 ISOlat1 -->
<!ENTITY ograve CDATA "ò" -- latin small letter o with grave,
U+00F2 ISOlat1 -->
<!ENTITY oacute CDATA "ó" -- latin small letter o with acute,
U+00F3 ISOlat1 -->
<!ENTITY ocirc CDATA "ô" -- latin small letter o with circumflex,
U+00F4 ISOlat1 -->
<!ENTITY otilde CDATA "õ" -- latin small letter o with tilde,
U+00F5 ISOlat1 -->
<!ENTITY ouml CDATA "ö" -- latin small letter o with diaeresis,
U+00F6 ISOlat1 -->
<!ENTITY divide CDATA "÷" -- division sign, U+00F7 ISOnum -->
<!ENTITY oslash CDATA "ø" -- latin small letter o with stroke,
= latin small letter o slash,
U+00F8 ISOlat1 -->
<!ENTITY ugrave CDATA "ù" -- latin small letter u with grave,
U+00F9 ISOlat1 -->
<!ENTITY uacute CDATA "ú" -- latin small letter u with acute,
U+00FA ISOlat1 -->
<!ENTITY ucirc CDATA "û" -- latin small letter u with circumflex,
U+00FB ISOlat1 -->
<!ENTITY uuml CDATA "ü" -- latin small letter u with diaeresis,
U+00FC ISOlat1 -->
<!ENTITY yacute CDATA "ý" -- latin small letter y with acute,
U+00FD ISOlat1 -->
<!ENTITY thorn CDATA "þ" -- latin small letter thorn with,
U+00FE ISOlat1 -->
<!ENTITY yuml CDATA "ÿ" -- latin small letter y with diaeresis,
U+00FF ISOlat1 -->
24.3 Character entity references for symbols, mathematical symbols, and
Greek letters
The character entity references in this section produce characters that may
be represented by glyphs in the widely available Adobe Symbol font,
including Greek characters, various bracketing symbols, and a selection of
mathematical operators such as gradient, product, and summation symbols.
To support these entities, user agents may support full [ISO10646] or use
other means. Display of glyphs for these characters may be obtained by being
able to display the relevant [ISO10646] characters or by other means, such
as internally mapping the listed entities, numeric character references, and
characters to the appropriate position in some font that contains the
requisite glyphs.
When to use Greek entities. This entity set contains all the letters used in
modern Greek. However, it does not include Greek punctuation, precomposed
accented characters nor the non-spacing accents (tonos, dialytika) required
to compose them. There are no archaic letters, Coptic-unique letters, or
precomposed letters for Polytonic Greek. The entities defined here are not
intended for the representation of modern Greek text and would not be an
efficient representation; rather, they are intended for occasional Greek
letters used in technical and mathematical works.
24.3.1 The list of characters
<!-- Mathematical, Greek and Symbolic characters for HTML -->
<!-- Character entity set. Typical invocation:
<!ENTITY % HTMLsymbol PUBLIC
"-//W3C//ENTITIES Symbols//EN//HTML">
%HTMLsymbol; -->
<!-- Portions © International Organization for Standardization 1986:
Permission to copy in any form is granted for use with
conforming SGML systems and applications as defined in
ISO 8879, provided this notice is included in all copies.
-->
<!-- Relevant ISO entity set is given unless names are newly introduced.
New names (i.e., not in ISO 8879 list) do not clash with any
existing ISO 8879 entity names. ISO 10646 character numbers
are given for each character, in hex. CDATA values are decimal
conversions of the ISO 10646 values and refer to the document
character set. Names are Unicode 2.0 names.
-->
<!-- Latin Extended-B -->
<!ENTITY fnof CDATA "ƒ" -- latin small f with hook = function
= florin, U+0192 ISOtech -->
<!-- Greek -->
<!ENTITY Alpha CDATA "Α" -- greek capital letter alpha, U+0391 -->
<!ENTITY Beta CDATA "Β" -- greek capital letter beta, U+0392 -->
<!ENTITY Gamma CDATA "Γ" -- greek capital letter gamma,
U+0393 ISOgrk3 -->
<!ENTITY Delta CDATA "Δ" -- greek capital letter delta,
U+0394 ISOgrk3 -->
<!ENTITY Epsilon CDATA "Ε" -- greek capital letter epsilon, U+0395 -->
<!ENTITY Zeta CDATA "Ζ" -- greek capital letter zeta, U+0396 -->
<!ENTITY Eta CDATA "Η" -- greek capital letter eta, U+0397 -->
<!ENTITY Theta CDATA "Θ" -- greek capital letter theta,
U+0398 ISOgrk3 -->
<!ENTITY Iota CDATA "Ι" -- greek capital letter iota, U+0399 -->
<!ENTITY Kappa CDATA "Κ" -- greek capital letter kappa, U+039A -->
<!ENTITY Lambda CDATA "Λ" -- greek capital letter lambda,
U+039B ISOgrk3 -->
<!ENTITY Mu CDATA "Μ" -- greek capital letter mu, U+039C -->
<!ENTITY Nu CDATA "Ν" -- greek capital letter nu, U+039D -->
<!ENTITY Xi CDATA "Ξ" -- greek capital letter xi, U+039E ISOgrk3 -->
<!ENTITY Omicron CDATA "Ο" -- greek capital letter omicron, U+039F -->
<!ENTITY Pi CDATA "Π" -- greek capital letter pi, U+03A0 ISOgrk3 -->
<!ENTITY Rho CDATA "Ρ" -- greek capital letter rho, U+03A1 -->
<!-- there is no Sigmaf, and no U+03A2 character either -->
<!ENTITY Sigma CDATA "Σ" -- greek capital letter sigma,
U+03A3 ISOgrk3 -->
<!ENTITY Tau CDATA "Τ" -- greek capital letter tau, U+03A4 -->
<!ENTITY Upsilon CDATA "Υ" -- greek capital letter upsilon,
U+03A5 ISOgrk3 -->
<!ENTITY Phi CDATA "Φ" -- greek capital letter phi,
U+03A6 ISOgrk3 -->
<!ENTITY Chi CDATA "Χ" -- greek capital letter chi, U+03A7 -->
<!ENTITY Psi CDATA "Ψ" -- greek capital letter psi,
U+03A8 ISOgrk3 -->
<!ENTITY Omega CDATA "Ω" -- greek capital letter omega,
U+03A9 ISOgrk3 -->
<!ENTITY alpha CDATA "α" -- greek small letter alpha,
U+03B1 ISOgrk3 -->
<!ENTITY beta CDATA "β" -- greek small letter beta, U+03B2 ISOgrk3 -->
<!ENTITY gamma CDATA "γ" -- greek small letter gamma,
U+03B3 ISOgrk3 -->
<!ENTITY delta CDATA "δ" -- greek small letter delta,
U+03B4 ISOgrk3 -->
<!ENTITY epsilon CDATA "ε" -- greek small letter epsilon,
U+03B5 ISOgrk3 -->
<!ENTITY zeta CDATA "ζ" -- greek small letter zeta, U+03B6 ISOgrk3 -->
<!ENTITY eta CDATA "η" -- greek small letter eta, U+03B7 ISOgrk3 -->
<!ENTITY theta CDATA "θ" -- greek small letter theta,
U+03B8 ISOgrk3 -->
<!ENTITY iota CDATA "ι" -- greek small letter iota, U+03B9 ISOgrk3 -->
<!ENTITY kappa CDATA "κ" -- greek small letter kappa,
U+03BA ISOgrk3 -->
<!ENTITY lambda CDATA "λ" -- greek small letter lambda,
U+03BB ISOgrk3 -->
<!ENTITY mu CDATA "μ" -- greek small letter mu, U+03BC ISOgrk3 -->
<!ENTITY nu CDATA "ν" -- greek small letter nu, U+03BD ISOgrk3 -->
<!ENTITY xi CDATA "ξ" -- greek small letter xi, U+03BE ISOgrk3 -->
<!ENTITY omicron CDATA "ο" -- greek small letter omicron, U+03BF NEW -->
<!ENTITY pi CDATA "π" -- greek small letter pi, U+03C0 ISOgrk3 -->
<!ENTITY rho CDATA "ρ" -- greek small letter rho, U+03C1 ISOgrk3 -->
<!ENTITY sigmaf CDATA "ς" -- greek small letter final sigma,
U+03C2 ISOgrk3 -->
<!ENTITY sigma CDATA "σ" -- greek small letter sigma,
U+03C3 ISOgrk3 -->
<!ENTITY tau CDATA "τ" -- greek small letter tau, U+03C4 ISOgrk3 -->
<!ENTITY upsilon CDATA "υ" -- greek small letter upsilon,
U+03C5 ISOgrk3 -->
<!ENTITY phi CDATA "φ" -- greek small letter phi, U+03C6 ISOgrk3 -->
<!ENTITY chi CDATA "χ" -- greek small letter chi, U+03C7 ISOgrk3 -->
<!ENTITY psi CDATA "ψ" -- greek small letter psi, U+03C8 ISOgrk3 -->
<!ENTITY omega CDATA "ω" -- greek small letter omega,
U+03C9 ISOgrk3 -->
<!ENTITY thetasym CDATA "ϑ" -- greek small letter theta symbol,
U+03D1 NEW -->
<!ENTITY upsih CDATA "ϒ" -- greek upsilon with hook symbol,
U+03D2 NEW -->
<!ENTITY piv CDATA "ϖ" -- greek pi symbol, U+03D6 ISOgrk3 -->
<!-- General Punctuation -->
<!ENTITY bull CDATA "•" -- bullet = black small circle,
U+2022 ISOpub -->
<!-- bullet is NOT the same as bullet operator, U+2219 -->
<!ENTITY hellip CDATA "…" -- horizontal ellipsis = three dot leader,
U+2026 ISOpub -->
<!ENTITY prime CDATA "′" -- prime = minutes = feet, U+2032 ISOtech -->
<!ENTITY Prime CDATA "″" -- double prime = seconds = inches,
U+2033 ISOtech -->
<!ENTITY oline CDATA "‾" -- overline = spacing overscore,
U+203E NEW -->
<!ENTITY frasl CDATA "⁄" -- fraction slash, U+2044 NEW -->
<!-- Letterlike Symbols -->
<!ENTITY weierp CDATA "℘" -- script capital P = power set
= Weierstrass p, U+2118 ISOamso -->
<!ENTITY image CDATA "ℑ" -- blackletter capital I = imaginary part,
U+2111 ISOamso -->
<!ENTITY real CDATA "ℜ" -- blackletter capital R = real part symbol,
U+211C ISOamso -->
<!ENTITY trade CDATA "™" -- trade mark sign, U+2122 ISOnum -->
<!ENTITY alefsym CDATA "ℵ" -- alef symbol = first transfinite cardinal,
U+2135 NEW -->
<!-- alef symbol is NOT the same as hebrew letter alef,
U+05D0 although the same glyph could be used to depict both characters -->
<!-- Arrows -->
<!ENTITY larr CDATA "←" -- leftwards arrow, U+2190 ISOnum -->
<!ENTITY uarr CDATA "↑" -- upwards arrow, U+2191 ISOnum-->
<!ENTITY rarr CDATA "→" -- rightwards arrow, U+2192 ISOnum -->
<!ENTITY darr CDATA "↓" -- downwards arrow, U+2193 ISOnum -->
<!ENTITY harr CDATA "↔" -- left right arrow, U+2194 ISOamsa -->
<!ENTITY crarr CDATA "↵" -- downwards arrow with corner leftwards
= carriage return, U+21B5 NEW -->
<!ENTITY lArr CDATA "⇐" -- leftwards double arrow, U+21D0 ISOtech -->
<!-- Unicode does not say that lArr is the same as the 'is implied by' arrow
but also does not have any other character for that function. So ? lArr can
be used for 'is implied by' as ISOtech suggests -->
<!ENTITY uArr CDATA "⇑" -- upwards double arrow, U+21D1 ISOamsa -->
<!ENTITY rArr CDATA "⇒" -- rightwards double arrow,
U+21D2 ISOtech -->
<!-- Unicode does not say this is the 'implies' character but does not have
another character with this function so ?
rArr can be used for 'implies' as ISOtech suggests -->
<!ENTITY dArr CDATA "⇓" -- downwards double arrow, U+21D3 ISOamsa -->
<!ENTITY hArr CDATA "⇔" -- left right double arrow,
U+21D4 ISOamsa -->
<!-- Mathematical Operators -->
<!ENTITY forall CDATA "∀" -- for all, U+2200 ISOtech -->
<!ENTITY part CDATA "∂" -- partial differential, U+2202 ISOtech -->
<!ENTITY exist CDATA "∃" -- there exists, U+2203 ISOtech -->
<!ENTITY empty CDATA "∅" -- empty set = null set = diameter,
U+2205 ISOamso -->
<!ENTITY nabla CDATA "∇" -- nabla = backward difference,
U+2207 ISOtech -->
<!ENTITY isin CDATA "∈" -- element of, U+2208 ISOtech -->
<!ENTITY notin CDATA "∉" -- not an element of, U+2209 ISOtech -->
<!ENTITY ni CDATA "∋" -- contains as member, U+220B ISOtech -->
<!-- should there be a more memorable name than 'ni'? -->
<!ENTITY prod CDATA "∏" -- n-ary product = product sign,
U+220F ISOamsb -->
<!-- prod is NOT the same character as U+03A0 'greek capital letter pi' though
the same glyph might be used for both -->
<!ENTITY sum CDATA "∑" -- n-ary sumation, U+2211 ISOamsb -->
<!-- sum is NOT the same character as U+03A3 'greek capital letter sigma'
though the same glyph might be used for both -->
<!ENTITY minus CDATA "−" -- minus sign, U+2212 ISOtech -->
<!ENTITY lowast CDATA "∗" -- asterisk operator, U+2217 ISOtech -->
<!ENTITY radic CDATA "√" -- square root = radical sign,
U+221A ISOtech -->
<!ENTITY prop CDATA "∝" -- proportional to, U+221D ISOtech -->
<!ENTITY infin CDATA "∞" -- infinity, U+221E ISOtech -->
<!ENTITY ang CDATA "∠" -- angle, U+2220 ISOamso -->
<!ENTITY and CDATA "∧" -- logical and = wedge, U+2227 ISOtech -->
<!ENTITY or CDATA "∨" -- logical or = vee, U+2228 ISOtech -->
<!ENTITY cap CDATA "∩" -- intersection = cap, U+2229 ISOtech -->
<!ENTITY cup CDATA "∪" -- union = cup, U+222A ISOtech -->
<!ENTITY int CDATA "∫" -- integral, U+222B ISOtech -->
<!ENTITY there4 CDATA "∴" -- therefore, U+2234 ISOtech -->
<!ENTITY sim CDATA "∼" -- tilde operator = varies with = similar to,
U+223C ISOtech -->
<!-- tilde operator is NOT the same character as the tilde, U+007E,
although the same glyph might be used to represent both -->
<!ENTITY cong CDATA "≅" -- approximately equal to, U+2245 ISOtech -->
<!ENTITY asymp CDATA "≈" -- almost equal to = asymptotic to,
U+2248 ISOamsr -->
<!ENTITY ne CDATA "≠" -- not equal to, U+2260 ISOtech -->
<!ENTITY equiv CDATA "≡" -- identical to, U+2261 ISOtech -->
<!ENTITY le CDATA "≤" -- less-than or equal to, U+2264 ISOtech -->
<!ENTITY ge CDATA "≥" -- greater-than or equal to,
U+2265 ISOtech -->
<!ENTITY sub CDATA "⊂" -- subset of, U+2282 ISOtech -->
<!ENTITY sup CDATA "⊃" -- superset of, U+2283 ISOtech -->
<!-- note that nsup, 'not a superset of, U+2283' is not covered by the Symbol
font encoding and is not included. Should it be, for symmetry?
It is in ISOamsn -->
<!ENTITY nsub CDATA "⊄" -- not a subset of, U+2284 ISOamsn -->
<!ENTITY sube CDATA "⊆" -- subset of or equal to, U+2286 ISOtech -->
<!ENTITY supe CDATA "⊇" -- superset of or equal to,
U+2287 ISOtech -->
<!ENTITY oplus CDATA "⊕" -- circled plus = direct sum,
U+2295 ISOamsb -->
<!ENTITY otimes CDATA "⊗" -- circled times = vector product,
U+2297 ISOamsb -->
<!ENTITY perp CDATA "⊥" -- up tack = orthogonal to = perpendicular,
U+22A5 ISOtech -->
<!ENTITY sdot CDATA "⋅" -- dot operator, U+22C5 ISOamsb -->
<!-- dot operator is NOT the same character as U+00B7 middle dot -->
<!-- Miscellaneous Technical -->
<!ENTITY lceil CDATA "⌈" -- left ceiling = apl upstile,
U+2308 ISOamsc -->
<!ENTITY rceil CDATA "⌉" -- right ceiling, U+2309 ISOamsc -->
<!ENTITY lfloor CDATA "⌊" -- left floor = apl downstile,
U+230A ISOamsc -->
<!ENTITY rfloor CDATA "⌋" -- right floor, U+230B ISOamsc -->
<!ENTITY lang CDATA "〈" -- left-pointing angle bracket = bra,
U+2329 ISOtech -->
<!-- lang is NOT the same character as U+003C 'less than'
or U+2039 'single left-pointing angle quotation mark' -->
<!ENTITY rang CDATA "〉" -- right-pointing angle bracket = ket,
U+232A ISOtech -->
<!-- rang is NOT the same character as U+003E 'greater than'
or U+203A 'single right-pointing angle quotation mark' -->
<!-- Geometric Shapes -->
<!ENTITY loz CDATA "◊" -- lozenge, U+25CA ISOpub -->
<!-- Miscellaneous Symbols -->
<!ENTITY spades CDATA "♠" -- black spade suit, U+2660 ISOpub -->
<!-- black here seems to mean filled as opposed to hollow -->
<!ENTITY clubs CDATA "♣" -- black club suit = shamrock,
U+2663 ISOpub -->
<!ENTITY hearts CDATA "♥" -- black heart suit = valentine,
U+2665 ISOpub -->
<!ENTITY diams CDATA "♦" -- black diamond suit, U+2666 ISOpub -->
24.4 Character entity references for markup-significant and
internationalization characters
The character entity references in this section are for escaping
markup-significant characters (these are the same as those in HTML 2.0 and
3.2), for denoting spaces and dashes. Other characters in this section apply
to internationalization issues such as the disambiguation of bidirectional
text (see the section on bidirectional text for details).
Entities have also been added for the remaining characters occurring in
CP-1252 which do not occur in the HTMLlat1 or HTMLsymbol entity sets. These
all occur in the 128 to 159 range within the cp-1252 charset. These entities
permit the characters to be denoted in a platform-independent manner.
To support these entities, user agents may support full [ISO10646] or use
other means. Display of glyphs for these characters may be obtained by being
able to display the relevant [ISO10646] characters or by other means, such
as internally mapping the listed entities, numeric character references, and
characters to the appropriate position in some font that contains the
requisite glyphs.
24.4.1 The list of characters
<!-- Special characters for HTML -->
<!-- Character entity set. Typical invocation:
<!ENTITY % HTMLspecial PUBLIC
"-//W3C//ENTITIES Special//EN//HTML">
%HTMLspecial; -->
<!-- Portions © International Organization for Standardization 1986:
Permission to copy in any form is granted for use with
conforming SGML systems and applications as defined in
ISO 8879, provided this notice is included in all copies.
-->
<!-- Relevant ISO entity set is given unless names are newly introduced.
New names (i.e., not in ISO 8879 list) do not clash with any
existing ISO 8879 entity names. ISO 10646 character numbers
are given for each character, in hex. CDATA values are decimal
conversions of the ISO 10646 values and refer to the document
character set. Names are Unicode 2.0 names.
-->
<!-- C0 Controls and Basic Latin -->
<!ENTITY quot CDATA """ -- quotation mark = APL quote,
U+0022 ISOnum -->
<!ENTITY amp CDATA "&" -- ampersand, U+0026 ISOnum -->
<!ENTITY lt CDATA "<" -- less-than sign, U+003C ISOnum -->
<!ENTITY gt CDATA ">" -- greater-than sign, U+003E ISOnum -->
<!-- Latin Extended-A -->
<!ENTITY OElig CDATA "Œ" -- latin capital ligature OE,
U+0152 ISOlat2 -->
<!ENTITY oelig CDATA "œ" -- latin small ligature oe, U+0153 ISOlat2 -->
<!-- ligature is a misnomer, this is a separate character in some languages -->
<!ENTITY Scaron CDATA "Š" -- latin capital letter S with caron,
U+0160 ISOlat2 -->
<!ENTITY scaron CDATA "š" -- latin small letter s with caron,
U+0161 ISOlat2 -->
<!ENTITY Yuml CDATA "Ÿ" -- latin capital letter Y with diaeresis,
U+0178 ISOlat2 -->
<!-- Spacing Modifier Letters -->
<!ENTITY circ CDATA "ˆ" -- modifier letter circumflex accent,
U+02C6 ISOpub -->
<!ENTITY tilde CDATA "˜" -- small tilde, U+02DC ISOdia -->
<!-- General Punctuation -->
<!ENTITY ensp CDATA " " -- en space, U+2002 ISOpub -->
<!ENTITY emsp CDATA " " -- em space, U+2003 ISOpub -->
<!ENTITY thinsp CDATA " " -- thin space, U+2009 ISOpub -->
<!ENTITY zwnj CDATA "" -- zero width non-joiner,
U+200C NEW RFC 2070 -->
<!ENTITY zwj CDATA "" -- zero width joiner, U+200D NEW RFC 2070 -->
<!ENTITY lrm CDATA "" -- left-to-right mark, U+200E NEW RFC 2070 -->
<!ENTITY rlm CDATA "" -- right-to-left mark, U+200F NEW RFC 2070 -->
<!ENTITY ndash CDATA "–" -- en dash, U+2013 ISOpub -->
<!ENTITY mdash CDATA "—" -- em dash, U+2014 ISOpub -->
<!ENTITY lsquo CDATA "‘" -- left single quotation mark,
U+2018 ISOnum -->
<!ENTITY rsquo CDATA "’" -- right single quotation mark,
U+2019 ISOnum -->
<!ENTITY sbquo CDATA "‚" -- single low-9 quotation mark, U+201A NEW -->
<!ENTITY ldquo CDATA "“" -- left double quotation mark,
U+201C ISOnum -->
<!ENTITY rdquo CDATA "”" -- right double quotation mark,
U+201D ISOnum -->
<!ENTITY bdquo CDATA "„" -- double low-9 quotation mark, U+201E NEW -->
<!ENTITY dagger CDATA "†" -- dagger, U+2020 ISOpub -->
<!ENTITY Dagger CDATA "‡" -- double dagger, U+2021 ISOpub -->
<!ENTITY permil CDATA "‰" -- per mille sign, U+2030 ISOtech -->
<!ENTITY lsaquo CDATA "‹" -- single left-pointing angle quotation mark,
U+2039 ISO proposed -->
<!-- lsaquo is proposed but not yet ISO standardized -->
<!ENTITY rsaquo CDATA "›" -- single right-pointing angle quotation mark,
U+203A ISO proposed -->
<!-- rsaquo is proposed but not yet ISO standardized -->
<!ENTITY euro CDATA "€" -- euro sign, U+20AC NEW -->